Source code: imrl-hdqn.
Introduction
Sparse reward problem is learning with little amount of reward from dynamic and complex environments. Learning in this setting requires the agent to explore the environment sufficiently. Several methods have been proposed to deal with this kind of environments, including curiosity-driven and subgoal discovery which means discover simple goals to achieve within the environment.
Environment
Four Rooms
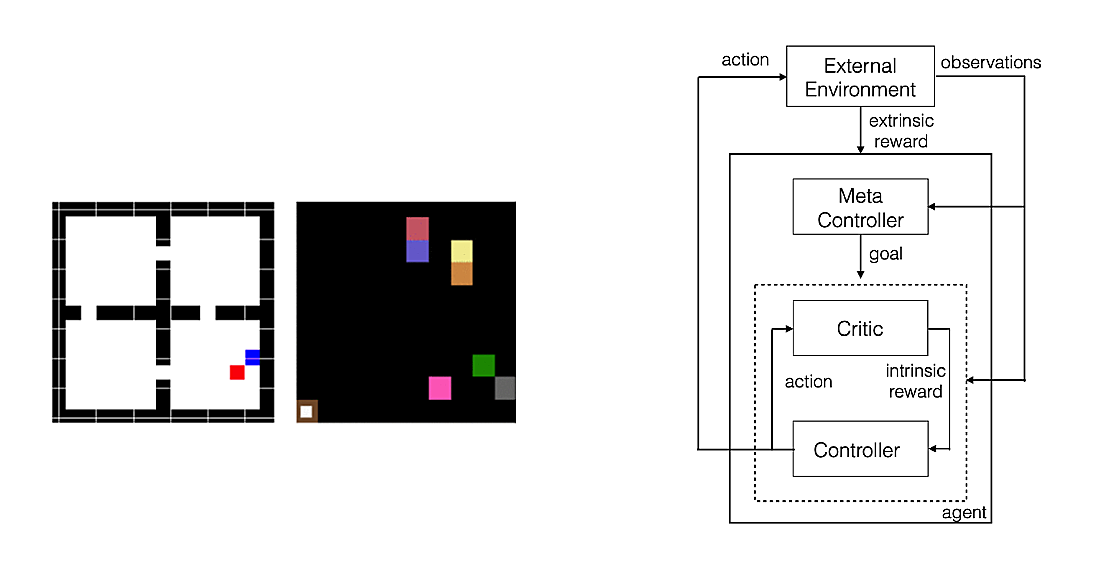
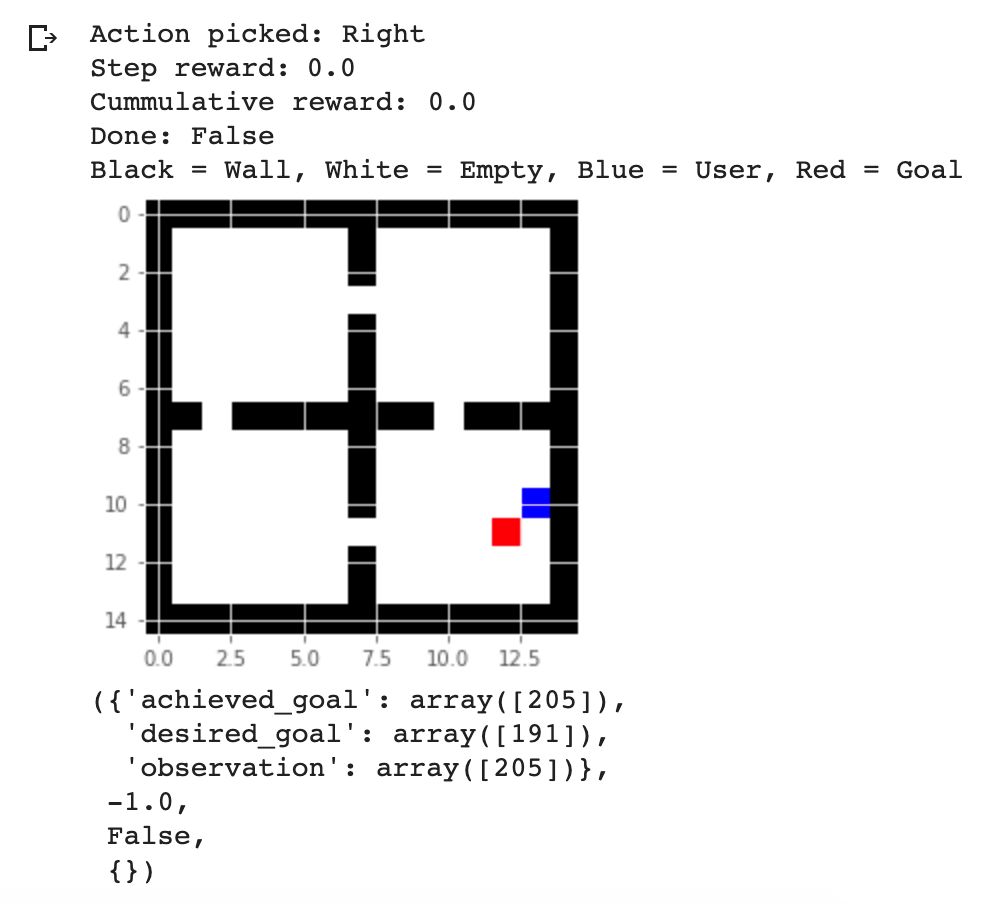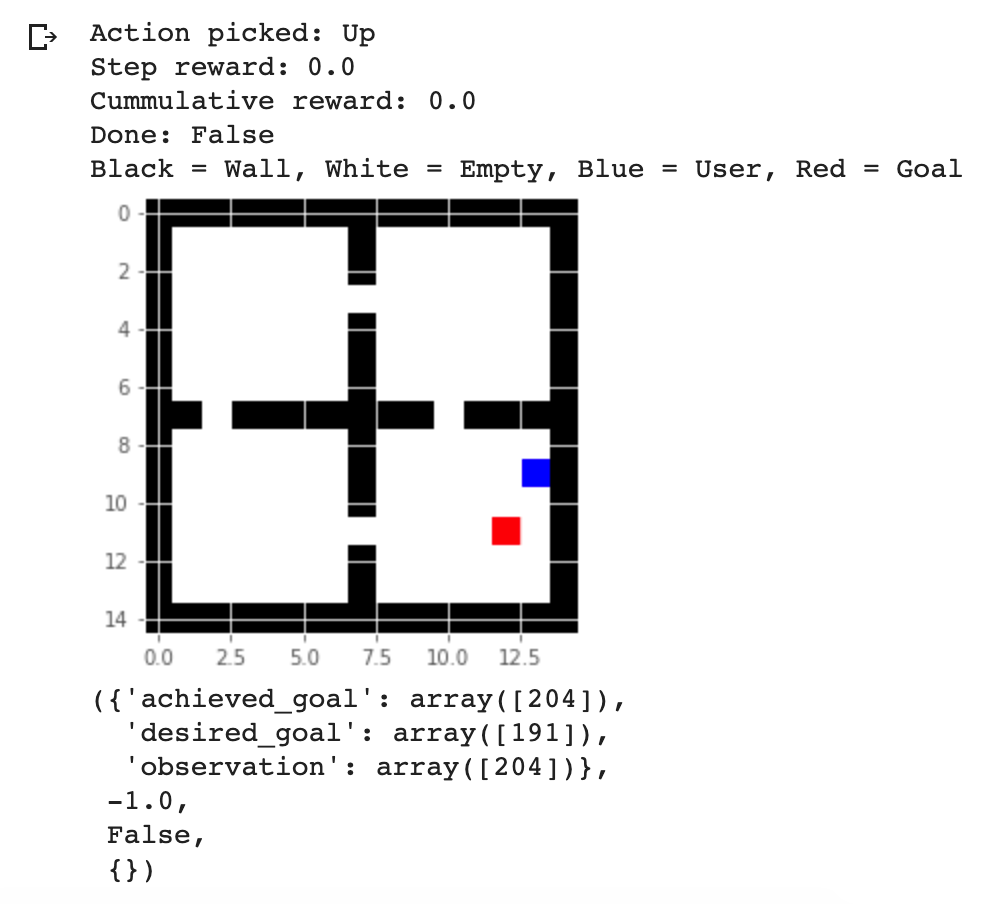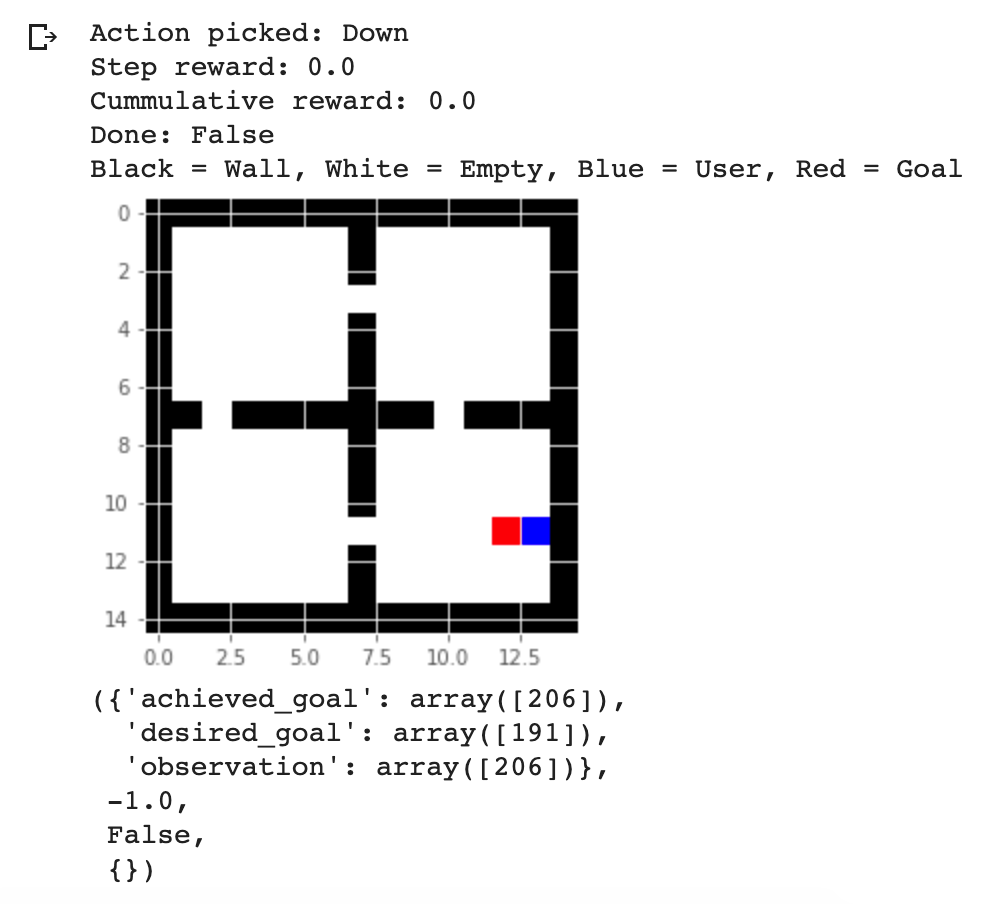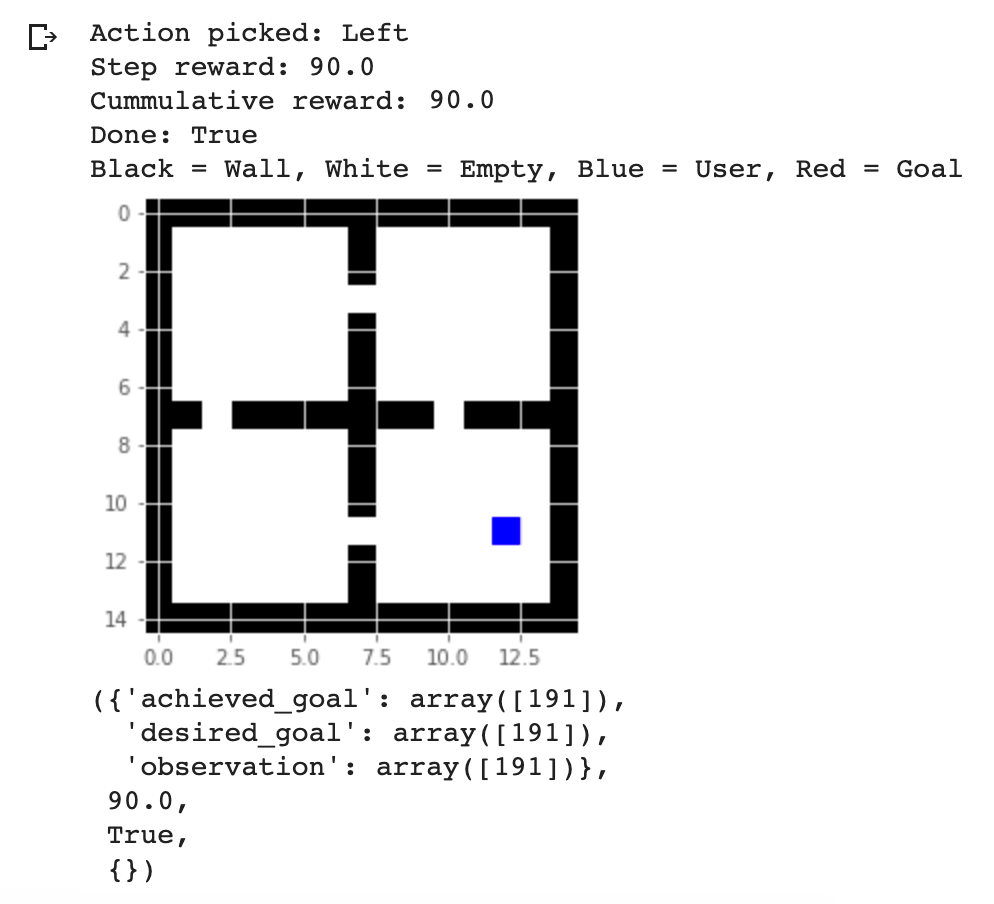
The first environment is a custom four rooms game environment with a Red goal randomly located in 1 of the 4 rooms. So this is a sparse environment with only one delay reward after a long chain of states and actions. The states and the subgoals will be grid locations, with subgoals as desired locations such as the hallways linking rooms. The agent will have 4 NEWS movements as actions.
Crafting World
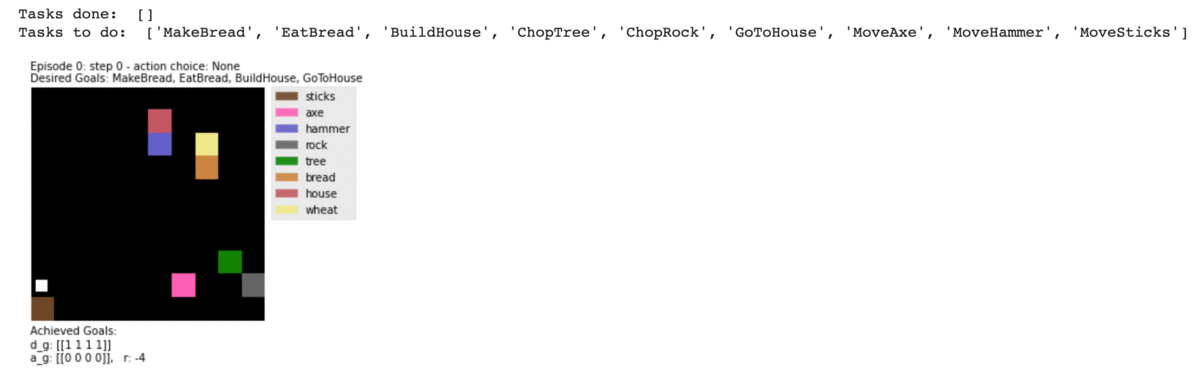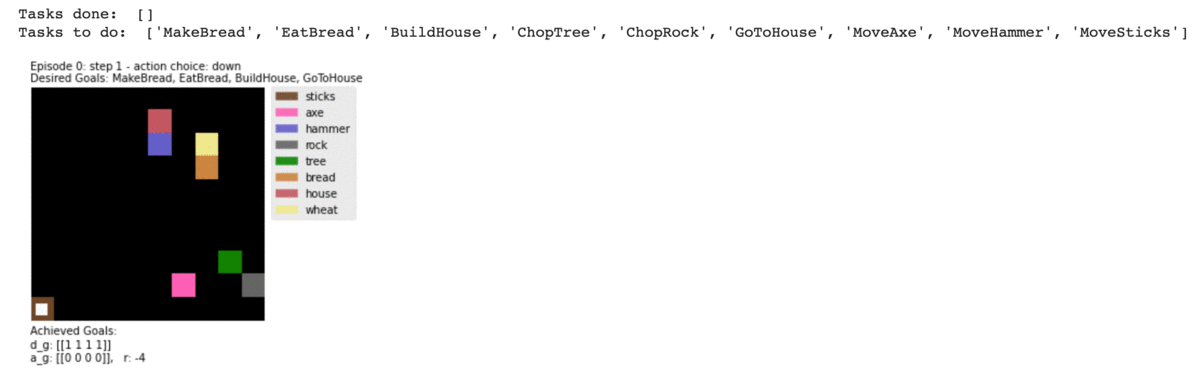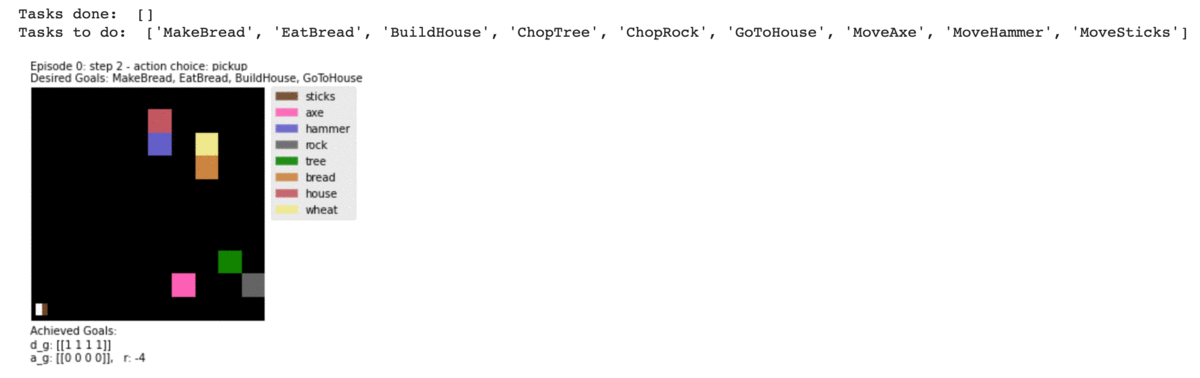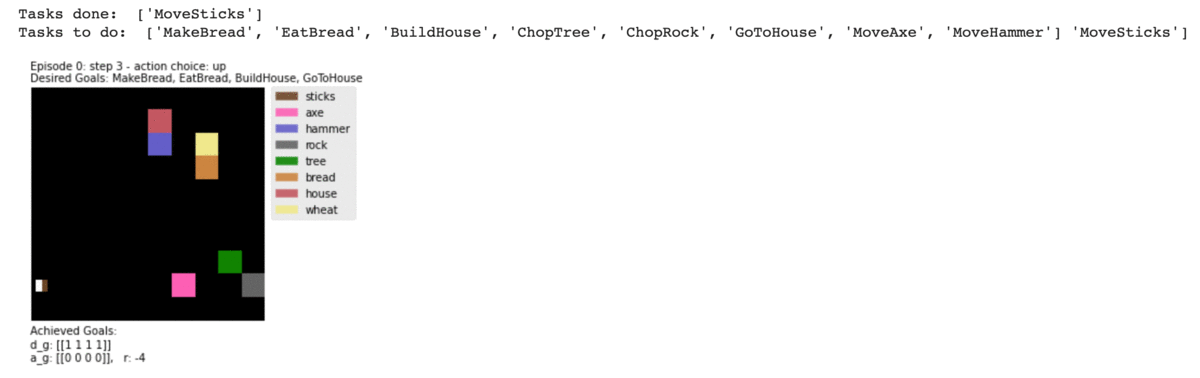
The environment has a list of objects, including pickable ones and blocking ones. We can define rewards as some of the available tasks to achieve. For example picking up tools and materials, building and making new objects. This makes the environment a dynamic one with location-changing objects. And also, the task done can be an outcome of sequential tasks, for example pick up the axe and bring it to the tree will transform the tree into sticks, and pick up the hammer and brings it to sticks can transform them into a house. The environment is under development so I couldn’t make the initial numbers of bread and house to 0. In my case, I defined MakeBread, EatBread, BuildHouse, GoToHouse as 4 rewards. I also implemented more functions to converted states and subgoals info from the environment the way I want. So in this case, the states and the subgoals will not be grid locations but the type of objects co-located with the agent. Besides 4 cardinal movement actions, the agent can pickup and drop objects.
Agent
Q-learning
h-DQN
The process involves choosing among different courses of action over a broad range of time scales, called temporal abstraction. The authors of the paper proposed an agent with 2 controllers. At each step, the lower controller chooses a one-step “primitive” action, while the meta-controller chooses a “multi-step” subgoal. Subgoal is a state that gives a maximum Q value, could be the state visited frequently in successful trajectories or the state with highest reward.
The notion of intrinsic reward is also introduced. Intrinsic motivation is carried out “for its own sake” without explicit reward from the env. How to compute a ‘good’ intrinsic reward functions is another challenge in RL. Many approaches define intrinsic motivation as curiosity. In our case, it is whether the subgoal is reached. So, in this approach, the agent produces actions and receives observations. Separate deep-Q networks are used inside the meta-controller and controller. The meta-controller looks at the raw states and produces a policy over subgoals, maximizing expected extrinsic reward. The controller takes in pairs of state and subgoal, and produces a policy over primitive actions, maximizing expected intrinsic reward. The internal critic checks if subgoal is reached and provides an appropriate intrinsic reward to the controller. The controller terminates when the episode ends or the subgoal is accomplished. The meta-controller then chooses a new subgoal and the process repeats.
Experiment
Four Rooms
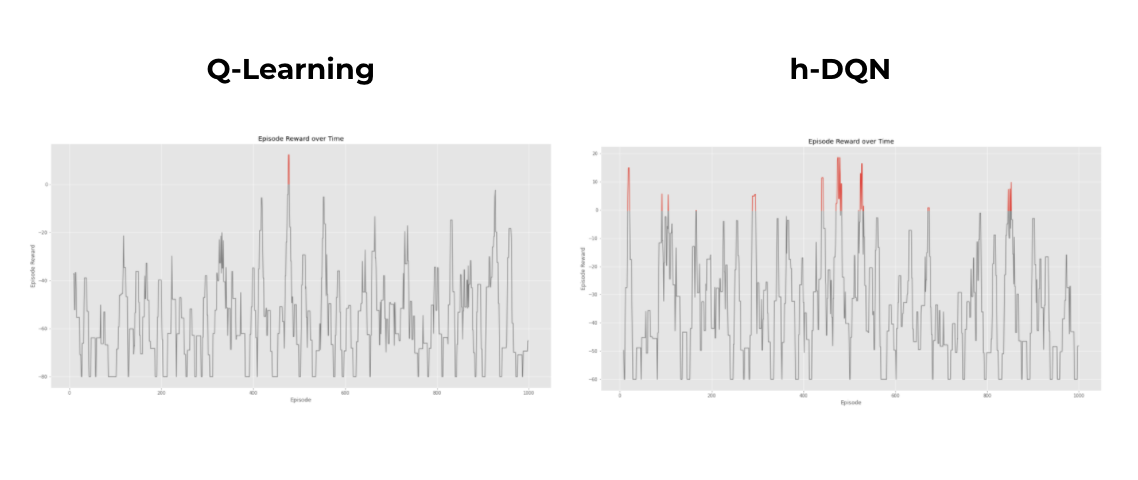
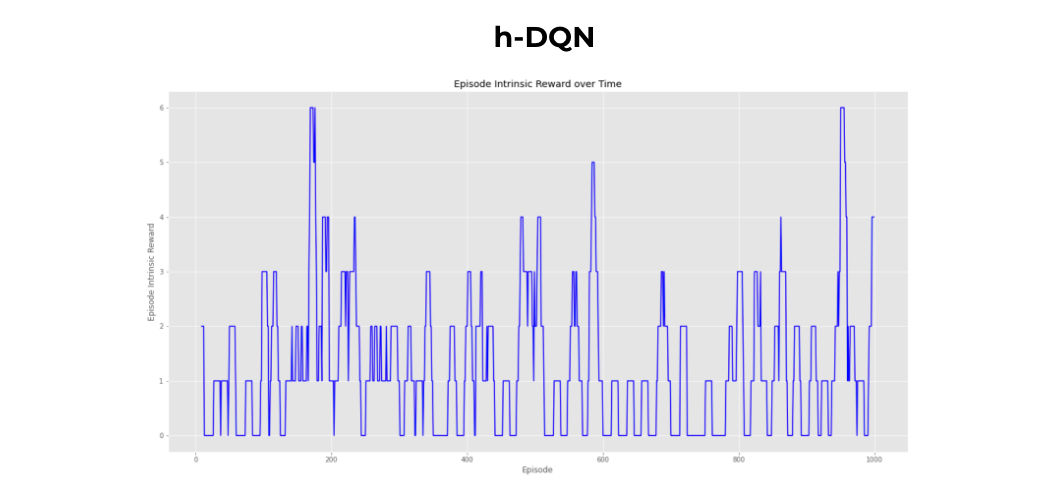
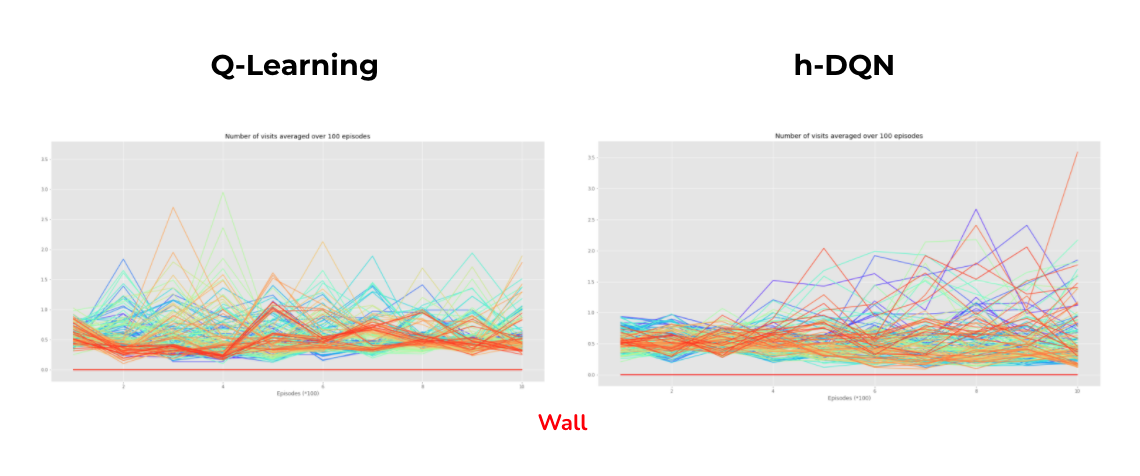
Crafting World
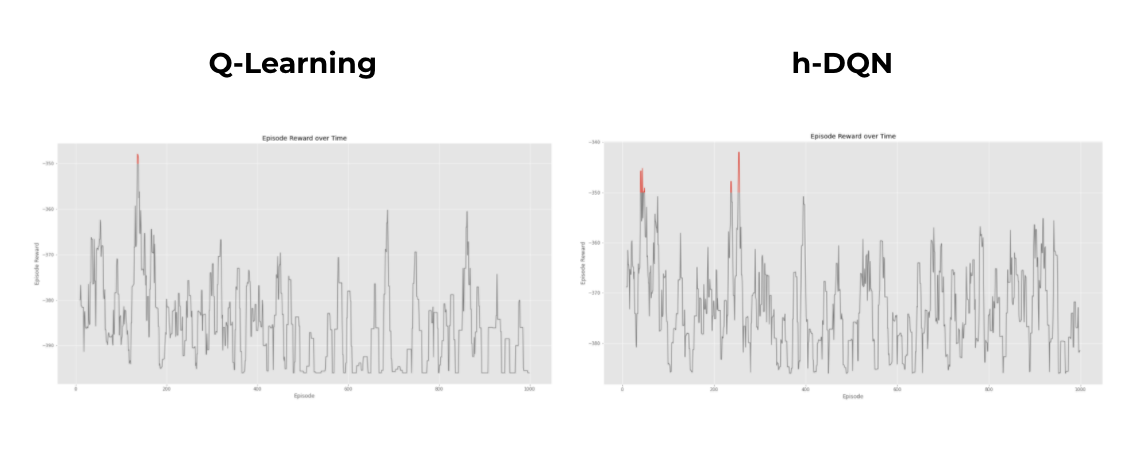
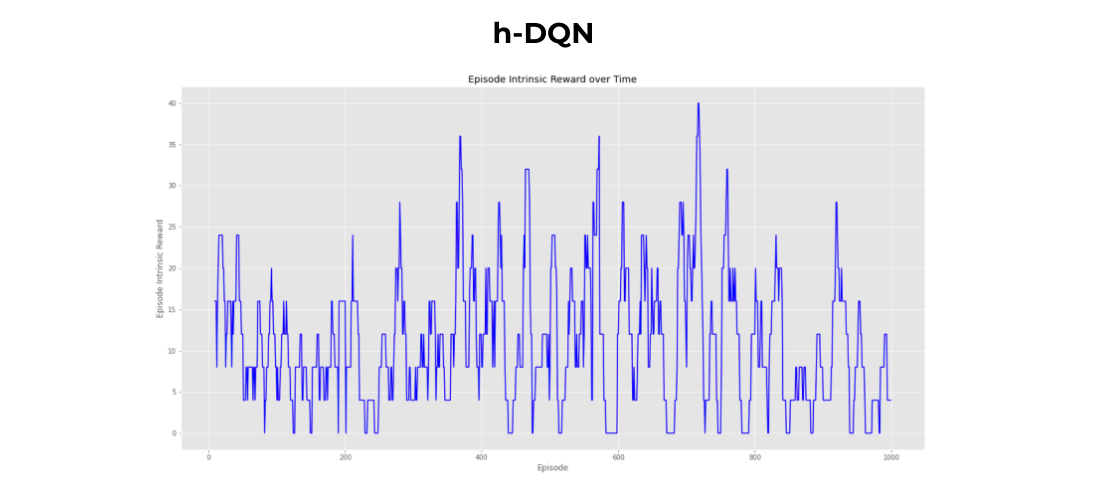
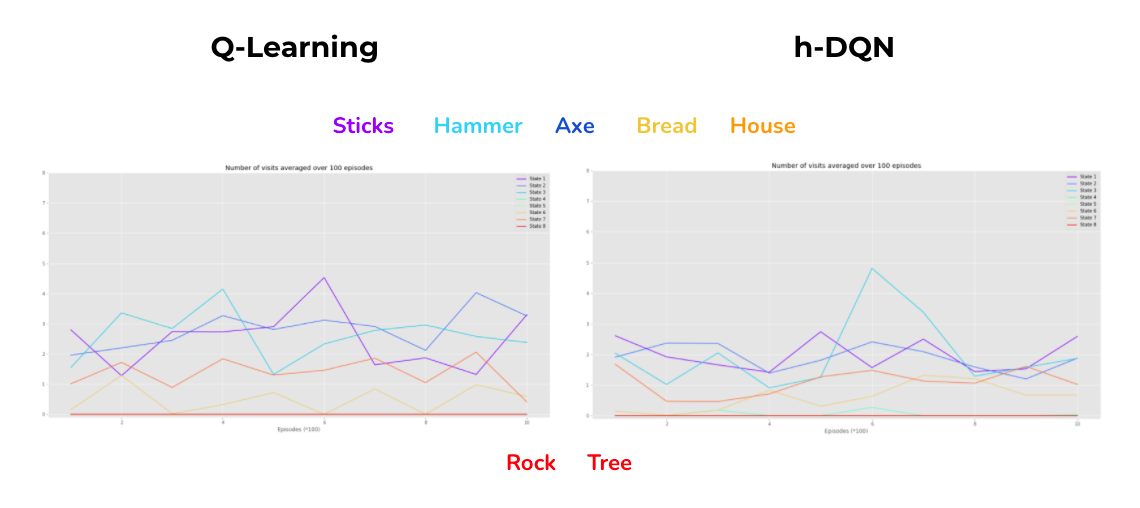
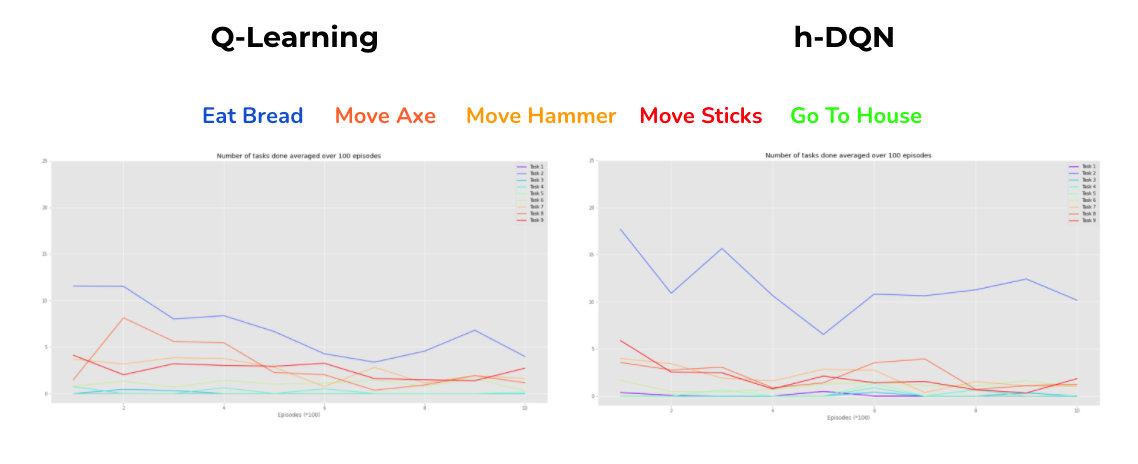
Future development
Think of a better definition of states and subgoals, potentially include storing an array of objects reached and sequential actions. Actually, there might be another approach taking into account that it would be impractical to learn every task independently, instead represent trajectories as the sum of the subtasks within them.